PUPR - OCR System
Project Overview
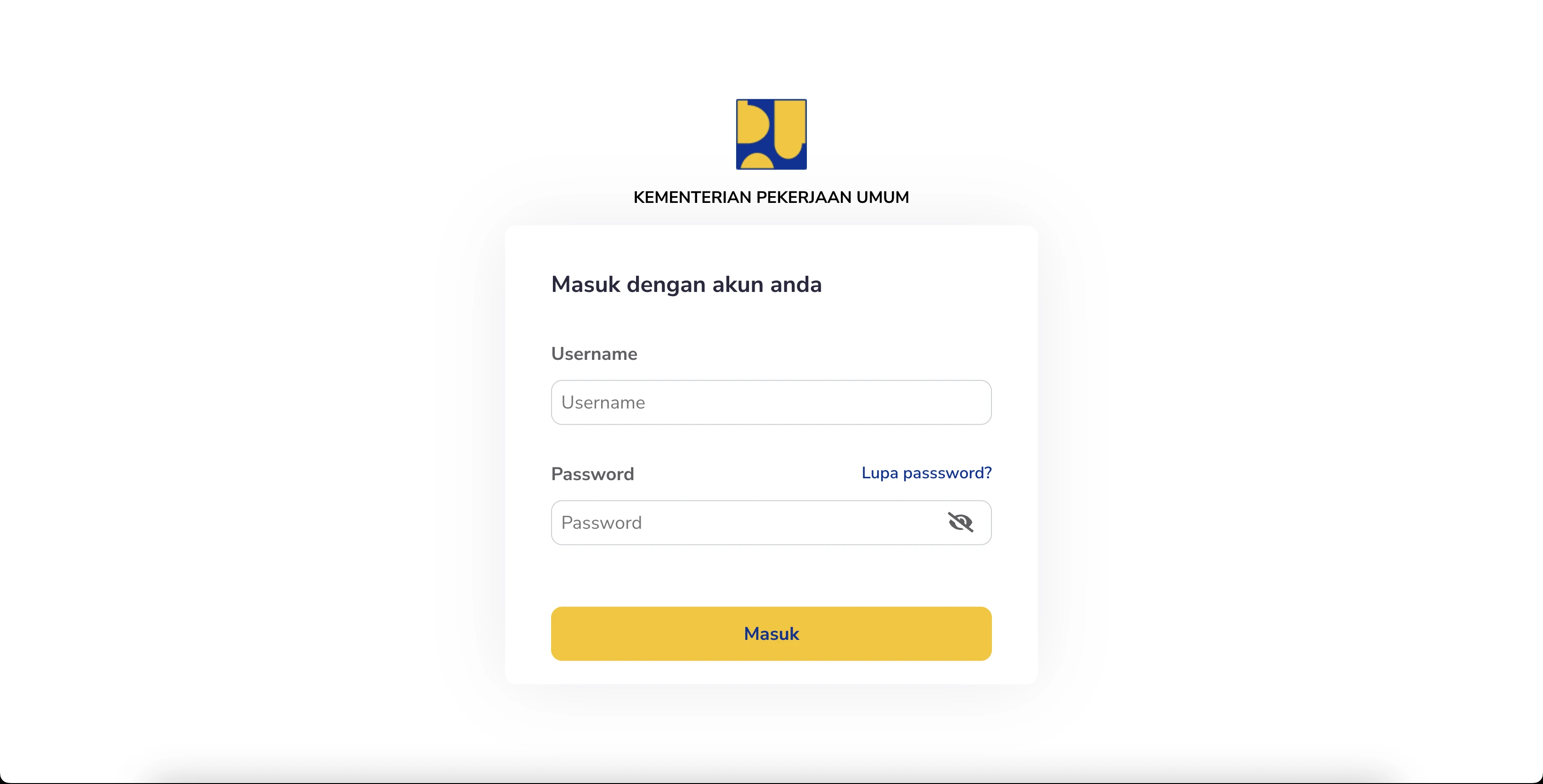
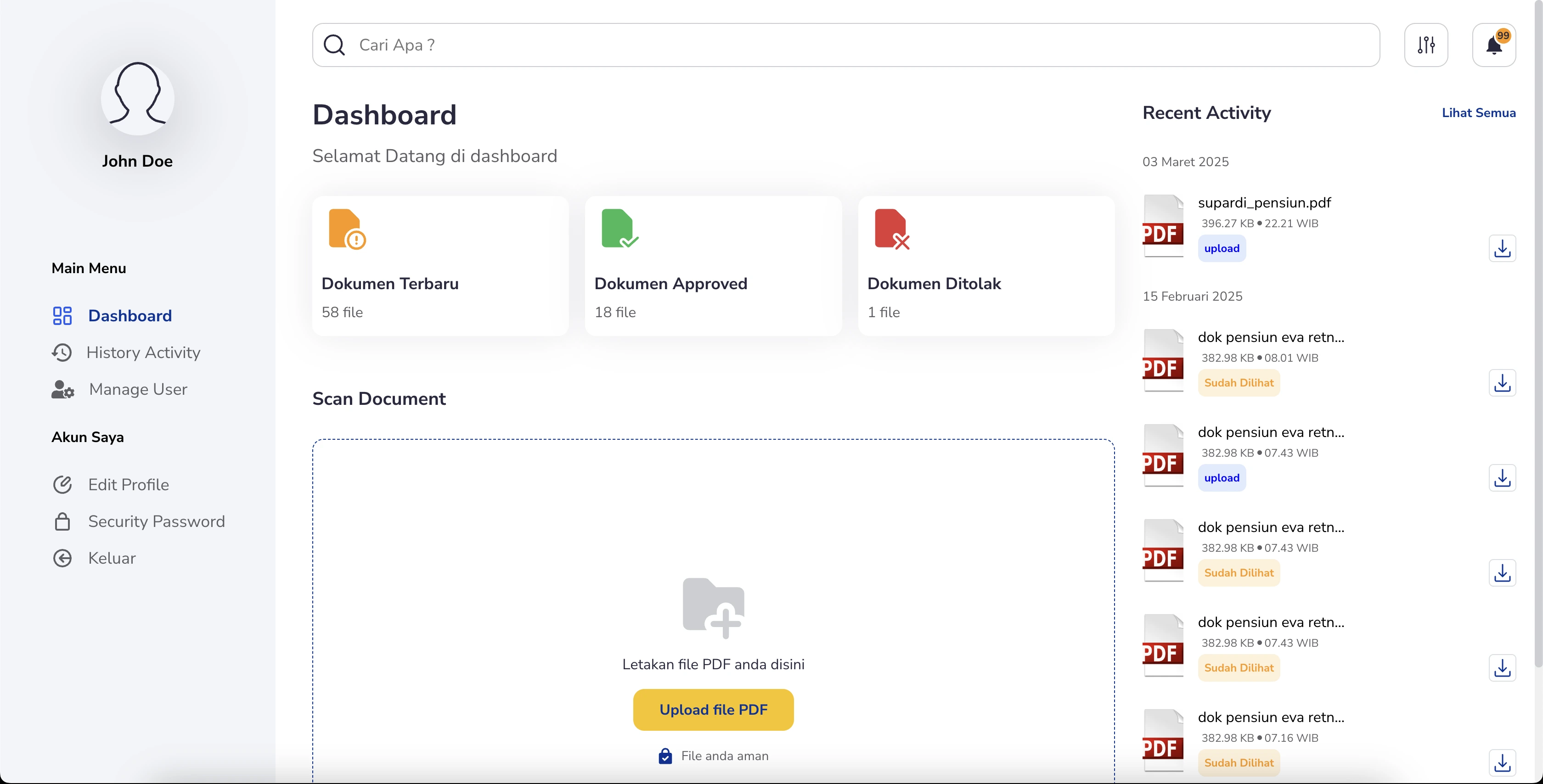
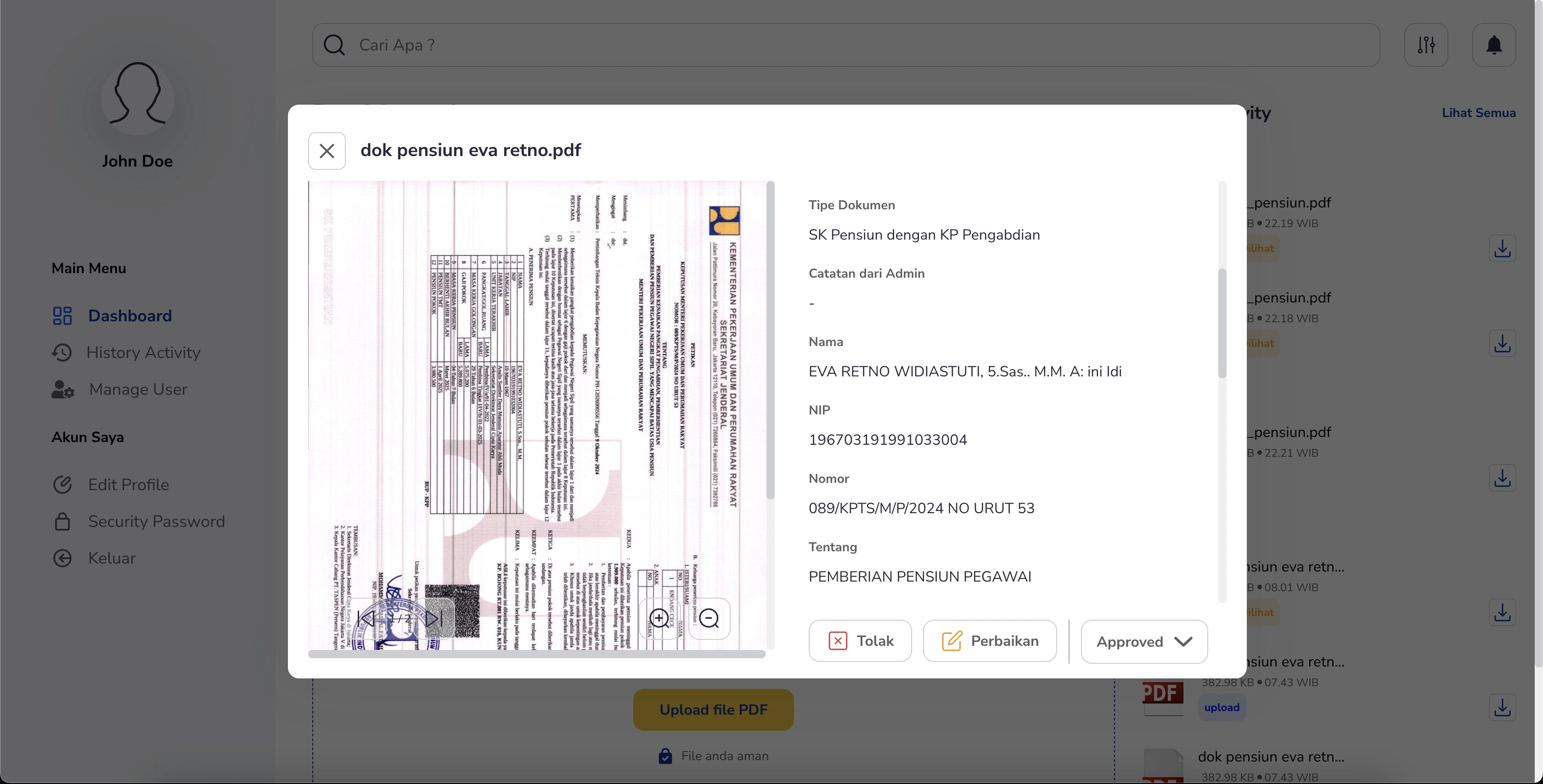
PUPR - OCR (Optical Character Recognition) System is a web-based platform that automates data extraction from various document types, enabling admins to upload documents and quickly retrieve key details—such
as name, NIP, email, and salary—without manual entry. The extracted data can be updated directly on the front end to account for OCR inaccuracies. Once approved, the verified
document is sent via open API to the PUPR system, streamlining document processing and integrating seamlessly with existing workflows.
Key Features
-
Enhanced Image Upload Quality:
- Utilizes TextCleaner and ImageMagick to pre-process and enhance the quality of uploaded document images.
- Automatically adjusts brightness, contrast, and sharpness to ensure that the OCR engine receives clear, high-resolution inputs for improved data extraction accuracy.
-
Optical Character Recognition (OCR):
- Employs a specialized OCR process that leverages regular expressions tailored for each document type.
- Converts raw extracted text into structured data points—such as name, NIP, email, and salary—ensuring that only the relevant and specific information is captured efficiently.
-
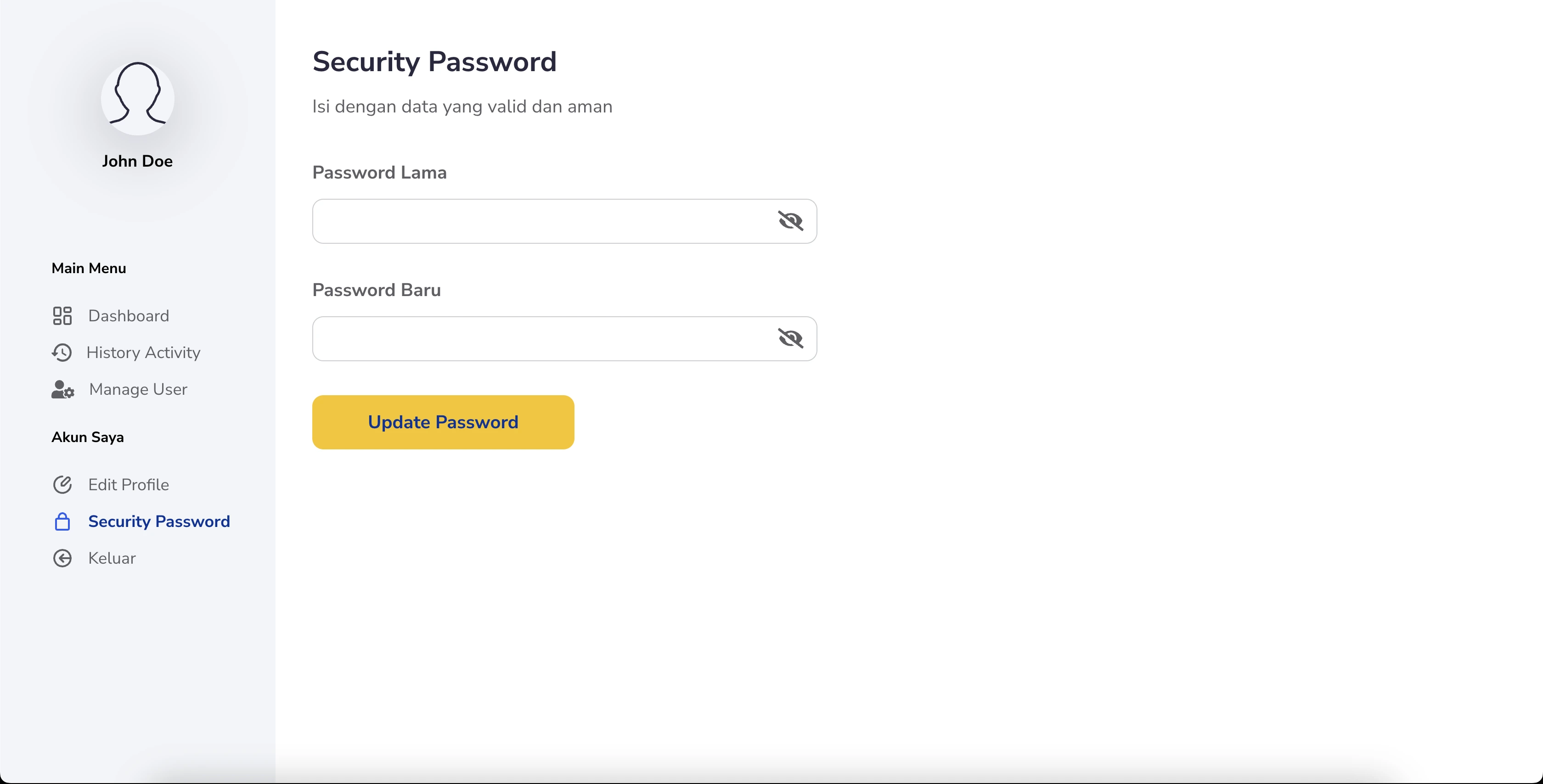
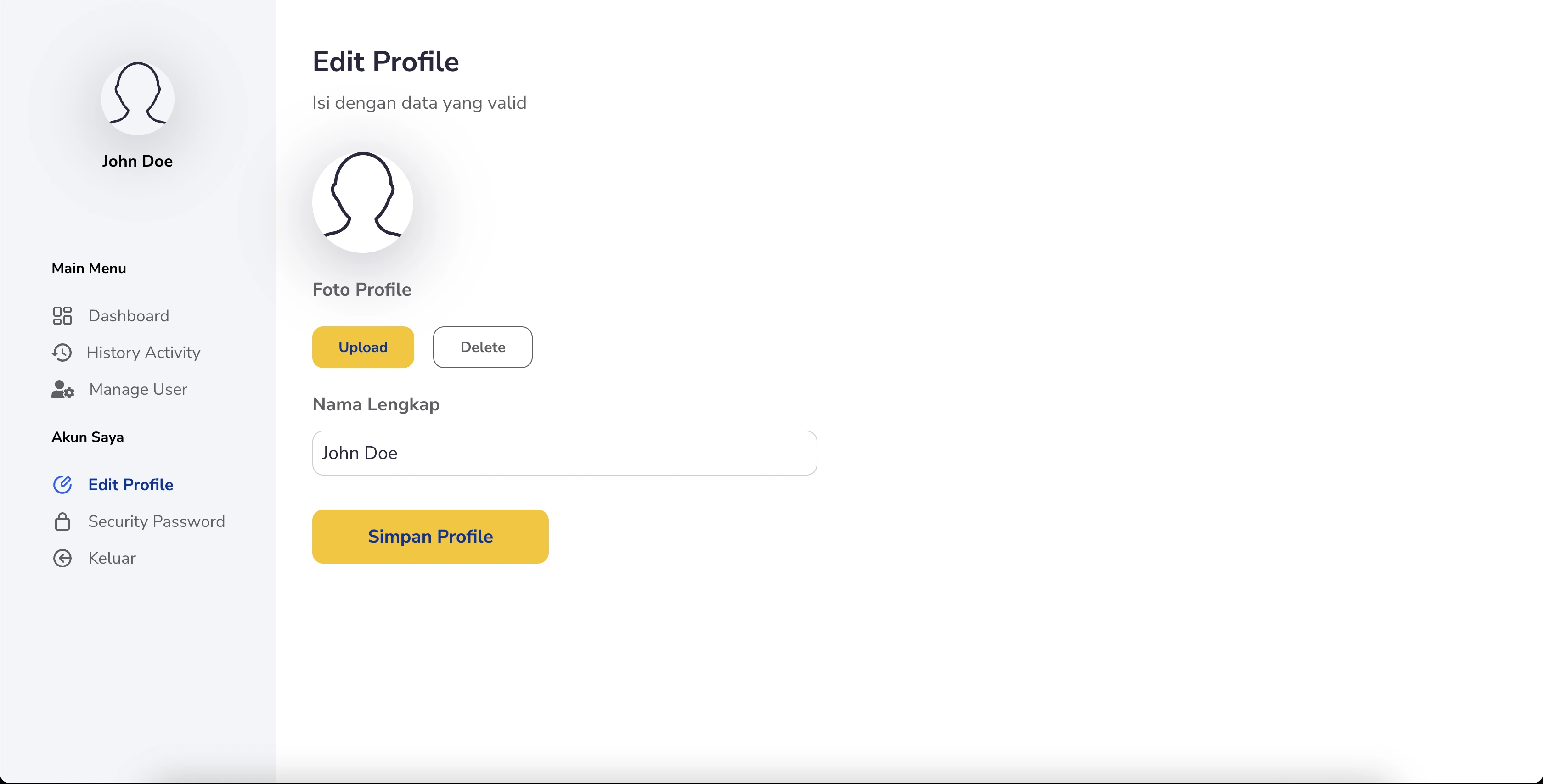
User-Friendly Data Update Interface:
- Allows administrators to review and edit the extracted data directly on the front end.
-
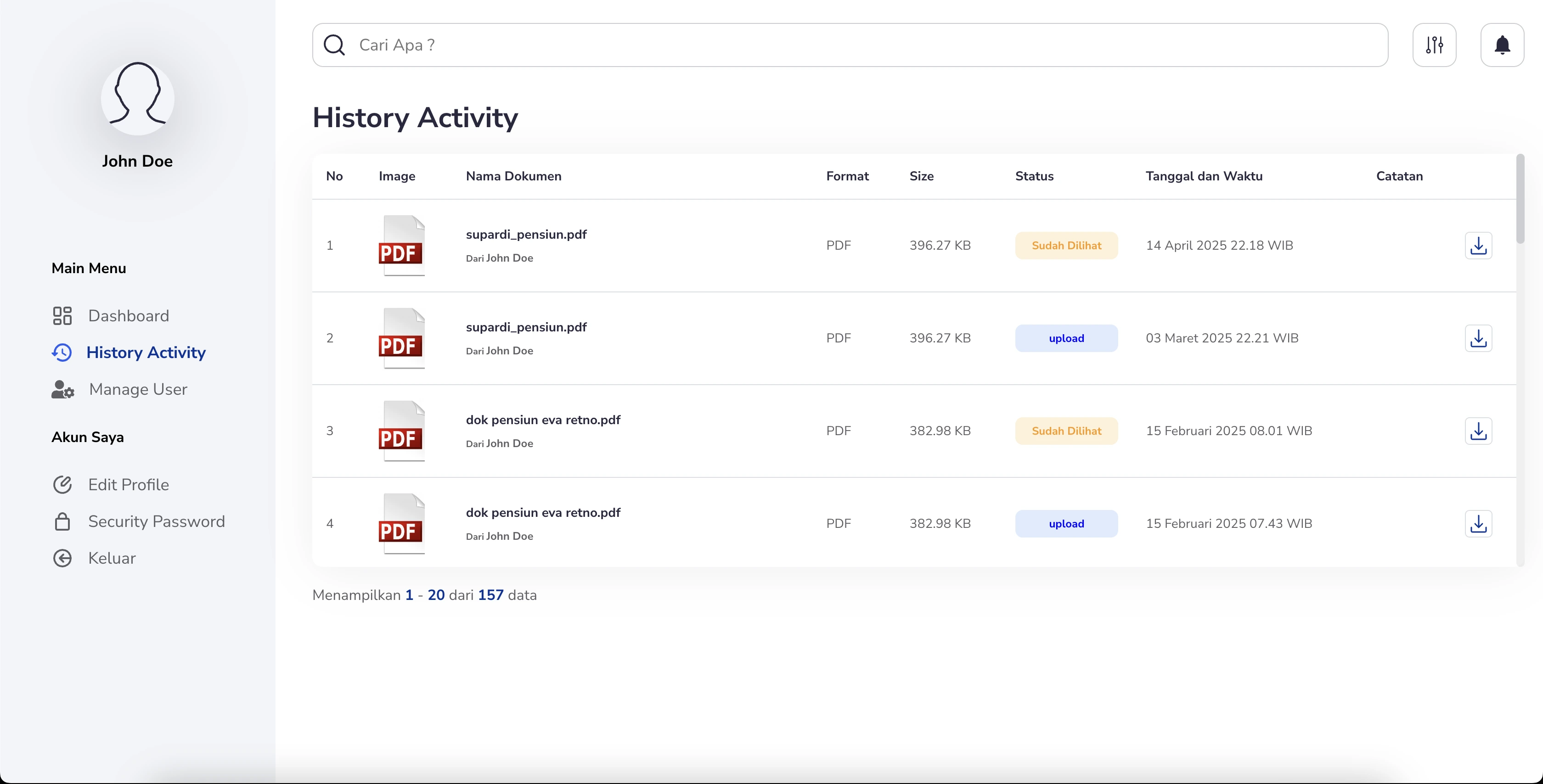
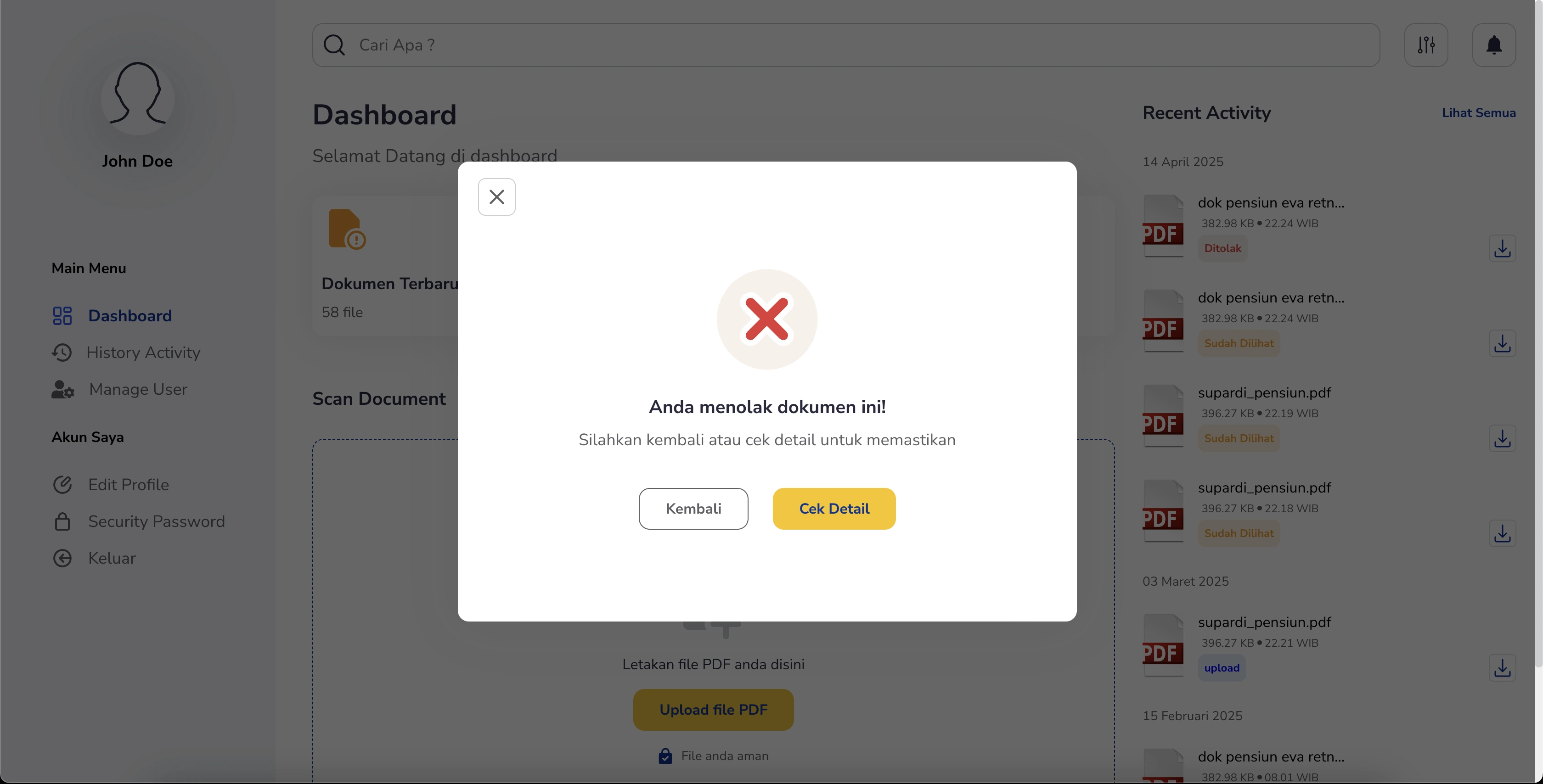
Document History Tracking:
- Maintains a complete history of each document’s lifecycle, from initial upload through to extraction, edits, approval, or rejection.
Technologies and Stack
-
Frontend:
- The user interface is built with
React.js, a well-known library for creating dynamic, responsive, and interactive web applications.
- The user interface is built with
-
Backend – Two Service Architecture:
- Primary API Service:
- Developed using
Node.jswithExpressas the HTTP framework, providing the main RESTful APIs to support user interactions and document processing. - Utilizes
Sequelizeas the ORM to manage database operations efficiently withPostgreSQL.
- Developed using
- OCR and Image Enhancement Service:
- A dedicated
Node.jsservice focused on scheduled tasks using cron jobs. - Responsible for running the OCR process and enhancing uploaded document images (applying tools like
TextCleanerandImageMagickas needed) to improve extraction accuracy.
- A dedicated
- Primary API Service:
-
Database:
- The project uses
PostgreSQLas its sole database, chosen for its reliability, robust performance, and powerful support for complex relational data.
- The project uses
My Role and Responsibilities
-
Update Image Processing Code:
- Updated the
textcleanermodule by switching from the'convert'command to the more efficientImageMagicklibrary.
- Updated the
-
Server Environment Setup:
- Configured utilities for deploying the application in both
stagingandproductionenvironments on the client’s cloud VPS secured by aVPN.
- Configured utilities for deploying the application in both
-
Implementation of Regex Validation:
- Developed and integrated a new regex checking system to support additional document types.
-
Open API Configuration for Document Approval:
- Set up an open API interface that enables seamless integration with the
PUPR EHRM Systemfor document approval processes.
- Set up an open API interface that enables seamless integration with the
Get In Touch
For business inquiries, collaborations, or further discussion about my projects, please feel free to reach out via email at [email protected]. You can also follow my work and stay updated on the latest developments by connecting with me on GitHub, LinkedIn, and Instagram.
Stay Curious and Happy Coding !!
← Back to projects